

行业中的广泛领域都基于既定因素进行投资,例如价值、动量和低风险。在这篇文章中,我们分享了在一段相当长且具有经济重要性的样本期内对样本外因素进行研究的主要结果。使用迄今为止最长的样本期(1866 年至 2020 年代),我们消除了对股票因素的数据挖掘和绩效衰退的担忧。我们发现,股票因素在样本外表现稳健,并且已成为金融市场 150 多年来一直存在的现象。
数据挖掘的担忧是真实存在的
我们为什么要进行这项研究?首先,需要对因子溢价进行更多研究,尤其是使用样本外数据。大多数从业者对股票因子的研究都使用可追溯到 1980 年代或 1990 年代的样本,涵盖约 40 至 50 年的时间。从统计学角度来看,这并不是大量的数据。此外,这些年是独一无二的,经济衰退很少,是历史上最长的扩张和牛市,而且直到 2021 年,通胀事件都很少。关于股票因子的学术研究通常使用更长的样本,通常从 1963 年开始使用芝加哥大学的美国证券价格研究中心(CRSP) 数据库。但想象一下,如果我们可以使用全面的股票价格数据集将样本长度加倍。早在 20 世纪之前,股票市场就对经济增长和创新融资至关重要。
其次,学术界已经发现了数百个因子,通常被称为“因子动物园”。最近的学术研究表明,这些因子中的许多可能是数据挖掘的结果,或者是学术界和行业研究人员进行大量测试而导致的统计误差。单次测试的置信度通常为 95%,这意味着每 20 次测试中就有一次会“发现”一个错误因子。当进行多次测试时,这个问题会变得更加严重。鉴于金融市场已经进行了数百万次测试,这一点至关重要。这是投资者的严重担忧,因为因子投资已成为全球主流。想象一下,如果推动数千亿美元投资的因子是统计噪音的结果,因此不太可能在未来带来回报。
图 1 说明了我们研究背后的动机之一。它显示了 CRSP 时代(1926 年后)的样本内和样本外期间规模、价值、动量和低风险因子的投资组合的检验统计数据。与早期研究一致,大多数因子在样本内期间表现出显著性。然而,结果在随后的样本外期间看起来有很大不同,几个因子在传统置信水平下失去了显著性。正如文献中所讨论的,股票因子表现的下降可以归因于多种原因,包括数据样本有限。无论如何,它强调了在足够大的样本中对股票因子进行独立的样本外测试的必要性。在我们的研究论文中,我们通过用 61 年的数据扩展 CRSP 数据集来在一个以前从未接触过的样本中对股票因子进行样本外测试来应对这一挑战。
图 1.
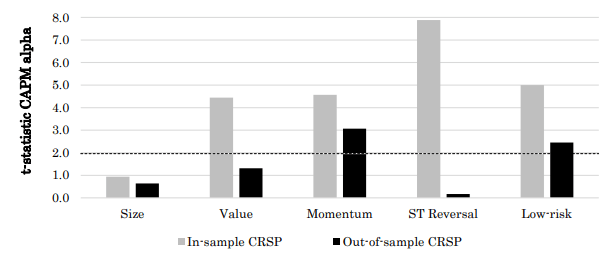

资料来源:全球金融数据,Kenneth French 网站,鹿特丹伊拉斯姆斯大学
19世纪的股票市场
在深入研究主要结果之前,让我们先概述一下 19 世纪的美国股市。在我们的论文中,我们收集了 1866 年至 1926 年(CRSP 数据集的开始日期)期间美国交易所上市的所有主要股票的信息。这一时期的特点是经济增长强劲、工业发展迅速,为美国成为世界领先的经济强国奠定了基础。股票市场在经济增长和创新融资中发挥了关键作用,市值在 60 年内增长了 50 多倍——与同期美国名义 GDP 增长一致。
19 世纪和 20 世纪的市场在很多方面都很相似。股票可以通过交易商在交易所轻松买卖,通过衍生品和期权进行交易,以保证金购买,并通过知名卖空者卖空。19 世纪的主要技术创新,如电报(1844 年)、跨大西洋电缆(1866 年)、股票行情纸带的引入(1867 年)、本地电话线的出现(1878 年)以及通过电缆进行的直接电话连接,促进了股票二级市场的流动性和活跃性、大量的经纪和做市活动、价格之间的快速套利、对信息的快速价格反应以及大量的交易活动。从东海岸到西海岸,甚至大西洋彼岸,价格报价都可以即时得知。与今天非常相似,投资者可以访问各种信誉良好的信息来源,而规模可观的金融分析师行业则提供市场评估和投资建议。
此外,19 世纪的交易成本与20世纪的成本相差无几。市场信息和学术研究表明,交易量较大的股票和套利良好的纽约证券交易所股票的交易成本约为 0.50%,但在两个世纪中,交易的最低价格均为 1/8 。此外,在第一次世界大战之前的十年中,纽约证券交易所的报价价差中位数为 86 个基点,四分之一的交易价差低于 36 个基点。此外,1900 年至 1926 年间,纽约证券交易所股票的股票周转率高于 2000 年。总体而言,自 19 世纪以来,美国股市一直是一个活跃且具有经济重要性的交易来源,为因子溢价提供了一个重要且可靠的样本外测试场地。
CRSP 之前的股票数据集
构建这个数据集是一项艰巨的工作。我们的样本包括自 1866 年以来所有主要股票的股票收益和特征。为什么是 1866 年?这是《商业和金融纪事报》的开始日期,也是 CRSP 数据库使用的关键来源。您可能想知道为什么 CRSP 从 1926 年开始。虽然确切原因仍是推测性的,但它似乎是任意的,确保包含 1929 年股市崩盘之前的一些数据。
在我们的论文中,我们手工收集了所有市值——与研究因子溢价和股票价格高度相关。此外,我们手工验证了从Global Financial Data(一家专门提供历史价格数据的数据提供商)获得的价格和股息数据样本。与 CRSP 不同,我们的数据收集重点是主要交易所交易的所有主要股票。这不仅包括纽约证券交易所,还包括纽约证券交易所(后来成为美国证券交易所,AMEX)和几个区域交易所。你可以想象这需要多少工作量,以及我们在鹿特丹伊拉斯姆斯大学利用了多少研究助理的时间。但结果是值得的。结果是 1866 年至 1926 年美国股票价格的高质量数据集,涵盖了大约 1,500 只上市股票。
因子的样本外表现是永恒的
那么,1866-1926 年 CRSP 之前时期的样本外结果如何?在讨论之前,请记住,这一时期之前尚未得到充分研究,因此我们可以对股权因子溢价进行真正的样本外测试。
图 2 总结了我们研究的主要结果。它显示了已建立的股票因子溢价在最长的 CRSP 样本(灰色)和 CRSP 之前的样本外时期(黑色)内的 alpha 值。有趣的是,价值、动量和低风险因子的样本外 alpha 与 CRSP 样本中观察到的非常相似。事实上,这两个样本之间的差异在统计上并不显著。150 多年的因子溢价证据(黑色条)证实了这一结论,显示出具有吸引力且在经济和统计上都具有高度显著性的溢价。总体而言,独立样本证实了价值、动量和低风险等关键股票因子溢价的有效性。
图 2.
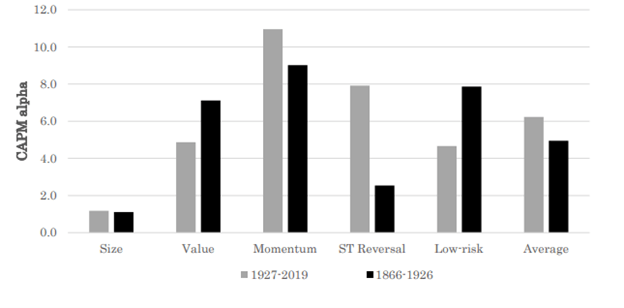
资料来源:全球金融数据,Kenneth French 网站,鹿特丹伊拉斯姆斯大学
这些发现让我们得出几个强有力的结论。首先,也是最重要的一点,因子溢价是金融市场的一个永恒特征。它们不是研究人员努力或特定经济条件的产物,而是自金融市场诞生以来就一直存在,持续了 150 多年。其次,因子溢价不会在样本外衰减,而是趋于保持稳定。第三,鉴于其持久性,因子溢价提供了重要的投资机会。这些结果应该会让投资者对因子溢价的稳健性更有信心,从而增强其在制定有效投资策略方面的效用。
韭菜热线原创版权所有,发布者:风生水起,转载请注明出处:https://www.9crx.com/86570.html




